

서론: 사용자가 “푸아송 분포로 축구 예상 스코어”를 찾는 이유

이 주제를 검색하는 사람은 대개 “몇 대 몇이 가장 그럴듯한가”를 숫자로 뽑아보고 싶어 한다, 단순 승패 예측보다 한 단계 더 들어가, 각 팀 득점이 몇 골일 확률이 높은지까지 보고 싶은 경우가 많다. 푸아송 분포는 일정 시간 동안 사건(득점)이 발생하는 횟수를 모델링하는 데 자주 쓰이기 때문에, 축구 득점처럼 ‘횟수’로 나타나는 결과와 결이 맞는다. 그렇지만 실제 경기는 전술 변화, 퇴장, 날씨, 심리 등 변수가 많아 완벽히 맞히는 도구라기보다 “합리적인 기준선”을 만드는 방법으로 이해되는 편이 자연스럽다. 따라서 이 글은 공식 자체보다, 사용자가 특히 스코어 확률표를 만들 때 어떤 입력값을 만들고 어떤 흐름으로 계산하는지에 초점을 맞춘다.
1) 푸아송 분포가 축구 스코어에 쓰이는 구조적 이유
득점 사건을 ‘횟수’로 보는 모델의 장점
푸아송 분포는 단위 시간(경기 90분) 동안 사건이 평균적으로 λ(람다)번 일어난다고 가정할 때, 정확히 k번 일어날 확률을 계산한다. 축구에서 사건은 득점이고. 중요한 점은 k는 0골, 1골, 2골처럼 정수 득점 수가 된다. 이 방식은 스코어를 “연속적인 실력”이 아니라 “발생 횟수”로 정리해 확률을 만들 수 있다는 점에서 실무적으로 편하다. 특히 특정 팀이 0골일 가능성, 3골 이상 폭발할 가능성처럼 의사결정에 필요한 구간을 바로 읽어낼 수 있다. 사용자는 결국 ‘예상 스코어 후보’와 그 확률을 보고 싶어 하므로, 분포 기반 접근이 검색 의도와 맞물린다.
기본 공식: P(X=k) = e^{-λ} λ^k / k!
푸아송 분포의 핵심은 “평균 득점 기대값 λ만 정하면” 0골부터 여러 골까지의 확률을 전부 계산할 수 있다는 점이다. 공식은 P(X=k)=e^{-λ}·λ^k/k!로 정리되며, e는 자연상수, k!는 팩토리얼이다, 예를 들어 λ=1.4라면, 0골 확률은 e^{-1.4}, 1골 확률은 e^{-1.4}·1.4, 2골 확률은 e^{-1.4}·1.4^2/2 같은 식으로 이어진다. 축구 예측에서 중요한 건 공식을 외우는 것보다, λ를 어떤 데이터에서 뽑을지와 그 λ가 어떤 의미를 갖는지다. 이 지점에서 사람마다 접근이 갈리며, 커뮤니티에서도 “λ 산출 방식”이 주된 토론 주제가 되곤 한다.
두 팀 스코어로 확장되는 지점: ‘각 팀 득점 분포’와 ‘결합 확률’
축구 스코어는 홈팀 득점과 원정팀 득점의 조합이므로, 실무에서는 팀별로 λ_home, λ_away를 만든다. 그리고 홈팀이 i골, 원정팀이 j골일 확률을 P(H=i)·P(A=j)로 계산해 스코어 매트릭스를 만든다. 여기에는 “두 팀 득점이 독립”이라는 단순화가 들어가며, 이 가정이 항상 맞지는 않지만 계산을 가능하게 해주는 출발점이 된다. 사용자는 이 매트릭스에서 확률이 가장 큰 칸(모드)을 ‘가장 그럴듯한 스코어’로 읽거나, 상위 몇 개 스코어를 후보군으로 뽑는다. 결과적으로 검색 의도는 “공식 → λ 설정 → 스코어표 산출”의 흐름을 기대하는 경우가 많다.
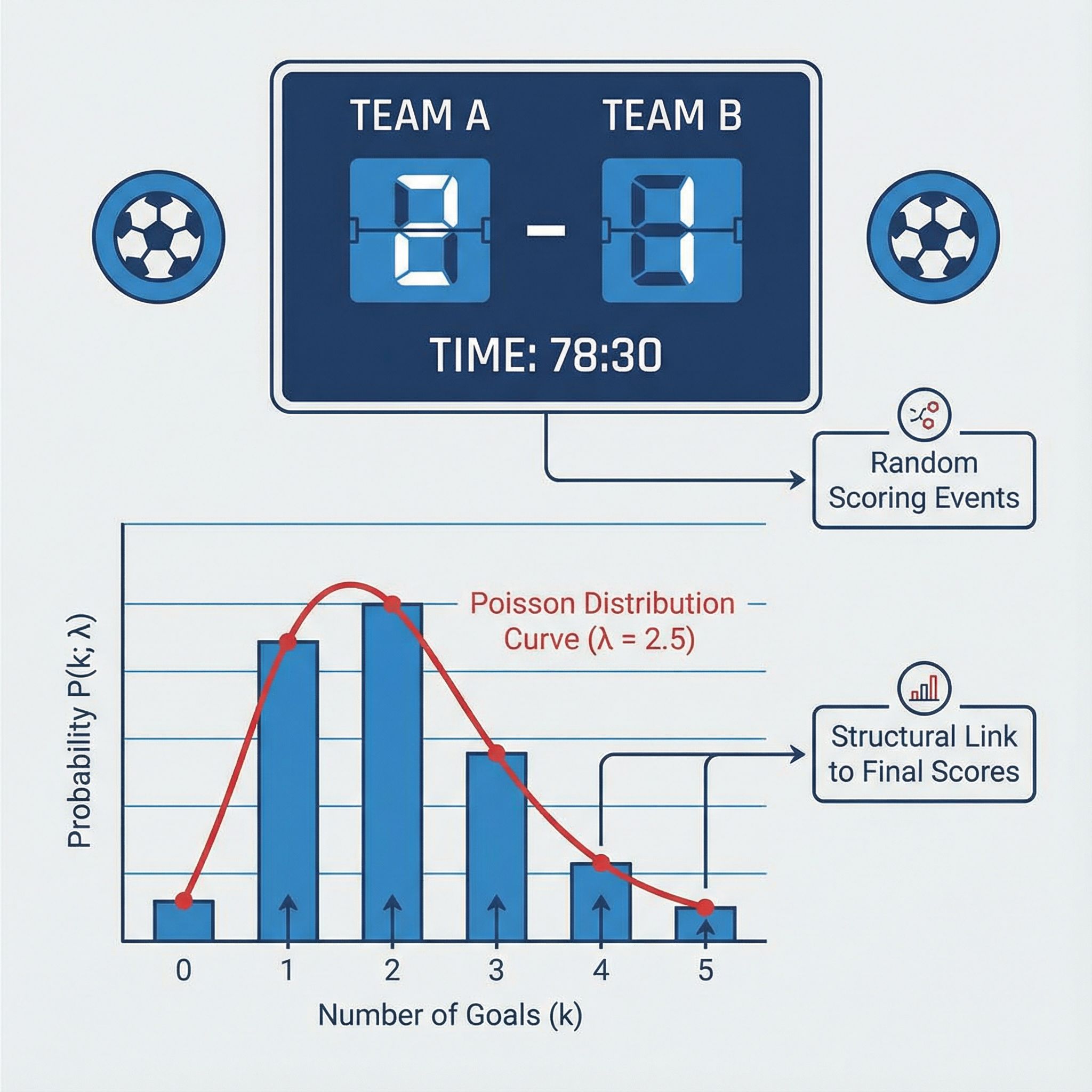
2) 예상 득점(λ)을 만드는 대표적 방법들
가장 단순한 접근: 팀 평균 득점/실점으로 λ 잡기
입문 단계에서 가장 흔한 방법은 해당 팀의 경기당 평균 득점과 실점을 활용하는 것이다. 예를 들어 홈팀의 공격력은 “홈 기준 경기당 득점”, 원정팀의 수비력은 “원정 기준 경기당 실점”처럼 나눠 본다. 그리고 두 값을 적당히 결합해 홈팀 λ를 만든다(예: 평균, 가중 평균, 리그 평균 대비 비율 적용 등), 단순한편 빠르게 계산할 수 있어, 많은 사용자가 이 단계에서 “내가 만든 스코어가 너무 극단적이지 않은지”를 확인한다. 다만 팀 전력이 급변했거나 표본이 적으면 λ가 흔들리기 쉽다는 한계가 따라온다.
리그 평균을 끼워 넣는 방식: 공격/수비 강도를 정규화
조금 더 자주 쓰이는 방식은 리그 평균 득점 환경을 기준선으로 두고, 팀의 공격 강도와 수비 강도를 비율로 계산하는 것이다. 예컨대 리그 홈팀 평균 득점이 1.50인데, 특정 팀의 홈 득점 평균이 1.80이면 홈 공격 강도는 1.80/1.50=1.20처럼 잡는다. 원정팀의 원정 실점 평균도 리그 평균 대비 비율로 바꿔 수비 강도를 만든다. 이후 홈팀 기대득점 λ_home을 “리그 홈 평균 득점 × 홈 공격 강도 × 원정 수비 약화(혹은 강도)”처럼 조합한다. 이 접근은 환경이 다른 리그나 시즌을 비교할 때도 구조가 유지되어, 커뮤니티에서 ‘기본 뼈대’로 공유되는 편이다.
최근 폼(가중치) 반영: 최신 경기일수록 더 크게 보기
사용자들이 자주 부딪히는 문제는 “시즌 평균이 현재 전력을 반영하지 못한다”는 점이다. 이를 보완하려고 최근 5경기, 10경기 등 구간을 두고 가중치를 적용하는 방식이 나온다. 예를 들어 10경기 평균을 쓰되, 최근 3경기에 1.5배 가중치를 주는 식으로 공격/수비 지표를 다시 계산한다. 이렇게 하면 부상 복귀, 감독 교체 후 전술 변화 같은 흐름이 λ에 조금 더 빨리 반영된다. 반면 표본이 줄어드는 만큼 변동성도 커져서, “과민 반응”이 되는지 여부를 따져보는 과정이 필요해진다.
xG(기대득점) 기반 λ: 득점 운을 분리하려는 시도
단순 득점/실점은 운의 영향이 크기 때문에. 이를 줄이려는 사람들은 xg(기대득점)와 xga(기대실점)를 활용한다. 팀이 만들어낸 찬스 품질을 누적한 xG는 실제 득점보다 안정적인 경우가 있어, λ의 입력값으로 쓰기에 매력적이다. 예컨대 최근 8경기 xG 평균을 공격 지표로, 상대의 xGA를 수비 지표로 두는 식이다. 다만 xG 데이터는 제공처마다 산정 방식이 달라 수치가 다르게 보일 수 있고, 사용자는 “어느 데이터 소스를 쓰는지”까지 확인하려는 경향이 있다. 그래서 xG 기반 모델은 계산 자체보다 데이터 신뢰와 일관성이 결과에 영향을 주는 편이다.
3) 스코어 확률표(매트릭스) 만들기: 실제 계산 흐름
1단계: λ_home, λ_away를 확정하고 범위를 정한다
계산을 시작하기 전에 홈과 원정의 기대득점 λ를 먼저 확정한다. 그 다음 0골부터 몇 골까지 확률을 계산할지 상한을 정하는데, 실무적으로는 5골 또는 6골까지면 대부분의 확률 질량을 커버한다. 리그나 팀 성향에 따라 7골까지 늘리기도 하지만, 목적이 “예상 스코어 후보”라면 과도하게 넓힐 필요는 없다. 사용자는 이 단계에서 λ가 너무 크거나 작지 않은지 감으로 점검하는데, 이 감 점검이 모델의 오류를 빨리 잡는 데 의외로 도움이 된다. 준비가 끝나면 각 팀의 푸아송 확률을 배열 형태로 만든다.
2단계: 팀별 득점 확률 벡터를 계산한다
홈팀에 대해 P(H=0)부터 P(H=6)까지, 원정팀에 대해 P(A=0)부터 P(A=6)까지를 푸아송 공식으로 계산한다. 예를 들어 λ_home=1.60이면 P(H=0)=e^{-1.6}, P(H=1)=e^{-1.6}·1.6, P(H=2)=e^{-1.6}·1.6^2/2처럼 이어진다. 같은 방식으로 원정팀도 계산하면, 두 개의 확률 벡터가 준비된다. 스프레드시트에서는 EXP(), POWER(), FACT() 같은 함수로 구현하는 경우가 많고, 코드에서는 팩토리얼과 지수 계산만 있으면 된다. 여기서 합이 1에 가깝게 나오는지(상한을 잘랐기 때문에 1보다 약간 작음)를 확인하는 습관이 자주 추천된다.
3단계: 결합 확률로 스코어 매트릭스를 채운다
홈 i골, 원정 j골의 확률은 P(H=i)×P(A=j)로 계산해 표를 채운다. 이 표는 행이 홈 득점, 열이 원정 득점인 형태로 구성되며, 각 칸이 특정 스코어의 발생 확률을 의미한다. 가장 확률이 큰 칸이 “최빈 스코어”가 되고, 상위 3~5개 칸을 모으면 현실적인 후보군이 된다. 사용자는 이 표를 통해 단순히 스코어뿐 아니라, 무승부가 얼마나 두꺼운지, 0-0이나 1-0 같은 저득점 구간이 강한지 같은 분위기도 읽는다. 이후 필요하면 승/무/패 확률, 오버/언더 확률로 재가공한다.
4단계: 승/무/패 및 오버/언더로 변환하는 방식
스코어 매트릭스가 있으면 승/무/패는 합산으로 나온다. 홈승 확률은 i>j인 칸의 확률을 모두 더하고, 무승부는 i=j 대각선 합, 원정승은 i<j 영역 합으로 계산한다. 오버/언더(예: 2.5 기준)는 i+j가 3 이상인 칸을 더하면 오버, 2 이하인 칸을 더하면 언더가 된다. 사용자는 “가장 그럴듯한 스코어”와 “시장형 지표(승무패, 득점라인)”를 함께 보고 싶어 하는 경우가 많아, 이 변환 단계가 실사용에서 자주 붙는다. 다만 여기서도 핵심은 매트릭스의 신뢰가 λ의 품질에 달려 있다는 점이다.
4) 모델을 현실에 맞추려는 보정 포인트와 해석 습관
독립 가정의 틈: 경기 양상 변화가 득점 분포를 흔든다
푸아송 기반 스코어 예측에서 가장 큰 단순화는 “홈팀 득점과 원정팀 득점이 독립”이라는 가정이다. 실제로는 선제골 이후 라인이 내려가거나, 한 팀이 퇴장당해 수비적으로 무너지는 등 상호작용이 강하게 발생한다. 그래서 어떤 경기는 0-0 쪽으로 확률이 두꺼워지고, 어떤 경기는 한쪽 다득점으로 꼬리가 길어지는 식으로 분포가 달라진다, 사용자는 예측값이 빗나갔을 때 공식을 의심하기보다, 이런 경기 내 상호작용을 λ 하나로 담기 어려웠다는 점을 확인하게 된다. 이 모델은 ‘평균적 경기’에 강하고, 특이한 흐름에는 약해지는 경향이 있다.
홈 어드밴티지와 일정 요소: λ에 섞이는 외생 변수들
푸아송 기반 스코어 예측에서 가장 큰 단순화는 홈팀 득점과 원정팀 득점이 독립이라는 가정인데, 이 전제는 커뮤니티 내 과도한 칭찬 글이 먹튀 유도에 사용되는 패턴 분석처럼 표면적 지표만 보고 구조적 상호작용을 놓칠 때 생기는 오해와 닮아 있습니다. 실제 경기에서는 선제골 이후 라인이 내려가거나 퇴장으로 수비가 붕괴되는 등 상호작용이 강하게 발생해 어떤 경기는 0-0 쪽으로 확률이 두꺼워지고, 어떤 경기는 한쪽 다득점으로 꼬리가 길어집니다. 사용자는 예측값이 빗나갔을 때 공식을 의심하기보다 이런 경기 내 상호작용을 λ 하나로 담기 어려웠다는 점을 확인하게 되며, 이 모델이 평균적 경기에는 강하지만 특이한 흐름에는 약해지는 경향을 이해하게 됩니다.
커뮤니티에서 신뢰가 생기는 방식: 적중률보다 ‘재현 가능한 절차’
예상 스코어 모델은 한두 경기 맞히는 것보다. 장기적으로 어떤 편향을 갖는지 점검하는 과정이 중요하다. 그래서 의견 교류가 활발한 환경에서는 “나는 λ를 이렇게 만들었다”처럼 재현 가능한 절차를 공개하는 글이 신뢰를 얻는 편이다. 반대로 결과만 나열하면, 운이 좋았던 구간인지 실력이었는지 판단하기 어렵다. 푸아송 접근은 계산이 단순한 대신 입력값 선택이 결과를 좌우하기 때문에, 서로의 입력 정의를 비교하는 대화가 자주 생긴다. 결국 사용자는 공식을 배우는 동시에, 스스로의 산출 흐름을 정리하는 방법을 함께 찾게 된다.
해석의 현실적 기준: “정답 스코어”가 아니라 “확률이 높은 구간”
스코어는 경우의 수가 많아 단일 정답을 맞히기 어렵고, 1골 차이만 나도 완전히 다른 결과처럼 보인다, 그래서 푸아송 기반 예측은 ‘정확히 2-1’ 같은 단일 값보다, 1-0~2-1처럼 확률이 두꺼운 구간을 보는 데 더 잘 맞는다. 또한 가장 확률이 큰 스코어가 1-1이라 해도 그 확률이 10%대인 경우가 흔해, “가장 높다”와 “높다”를 구분해 읽는 습관이 필요하다. 사용자는 여기서 모델을 예언 도구로 오해하기보다, 불확실성을 수치로 정리하는 도구로 받아들이면 활용도가 올라간다. 이런 관점이 잡히면, 스코어 매트릭스는 단순한 숫자표가 아니라 경기 해석의 기준선으로 기능한다.
결론: 푸아송 공식은 간단하지만, 핵심은 λ를 만드는 관찰 흐름이다
푸아송 분포로 축구 예상 스코어를 산출하는 과정은 “팀별 기대득점 λ 설정 → 팀별 득점 확률 계산 → 결합 확률로 스코어 매트릭스 작성”으로 정리된다. 사용자가 실제로 확인하고 싶어 하는 지점은 공식 자체보다, 어떤 데이터로 λ를 잡아야 결과가 납득 가능한지에 가깝다. 평균 득점/실점, 리그 평균 대비 정규화, 최근 폼 가중치, xG 활용 같은 방식은 모두 λ를 더 현실적으로 만들려는 시도이며, 각 방식은 장단이 분명하다, 스코어 예측은 단일 정답을 맞히기보다 확률이 두꺼운 구간을 읽는 데 강점이 있고, 독립 가정과 외생 변수는 해석 단계에서 늘 염두에 두게 된다. 결국 이 방법은 경기 결과를 단정하기보다, 불확실한 스코어를 구조화해 비교 가능한 형태로 정리하는 데 의미가 남는다.