

다중 언어 코퍼스를 다룰 때, 진짜 골치 아픈 게 바로 레이블 충돌이죠. 언어마다 같은 단어도 다르게 태깅되고, 분류 기준도 제각각이라서... 이게 생각보다 단순한 문제가 아니더라고요.
효과적인 레이블 충돌 방지 로직을 설계하면 다중 언어 데이터의 품질과 일관성을 크게 향상시킬 수 있습니다. 이걸 무시하면 데이터 분석 결과도 엉뚱하게 나오고, 머신러닝 모델 성능도 그냥 바닥으로 떨어질 수밖에 없어요.
오늘은 레이블 충돌이 왜 생기는지, 그리고 실제로 어떻게 해결할 수 있을지—이런저런 경험도 곁들여서 얘기해보려고 합니다. 실무에서 바로 쓸 수 있는 팁도 좀 넣어볼게요.
다중 언어 코퍼스에서의 레이블 충돌 문제와 원인
다중 언어 코퍼스를 처리하다 보면, 레이블 충돌은 주로 언어별 태깅 체계 차이랑 문자 인코딩 문제에서 터지더라고요. 이런 충돌이 생기면 데이터가 뒤죽박죽되고, 모델 성능도 기대 이하로 나올 수밖에 없습니다.
레이블 충돌의 정의 및 발생 사례
레이블 충돌이란, 같은 데이터를 두고 서로 다른 레이블이 붙거나, 똑같은 레이블명이 전혀 다른 의미로 쓰일 때를 말해요.
예를 들면, 한국어 코퍼스에서는 "명사"로 태깅된 단어가 영어 코퍼스에서는 "NN"으로 나오죠. 사실상 같은 건데, 시스템은 다르게 받아들이는 거죠.
품사 태깅에서 많이 보이는 사례를 하나 정리해보면:
| 언어 | 동사 레이블 | 형용사 레이블 |
|---|---|---|
| 한국어 | VV | VA |
| 영어 | VERB | ADJ |
| 일본어 | 動詞 | 形容詞 |
개체명 인식도 마찬가지예요. 한국어에선 "인명"인데, 영어에선 "PERSON"이라 시스템이 아예 별도로 취급해버리죠.
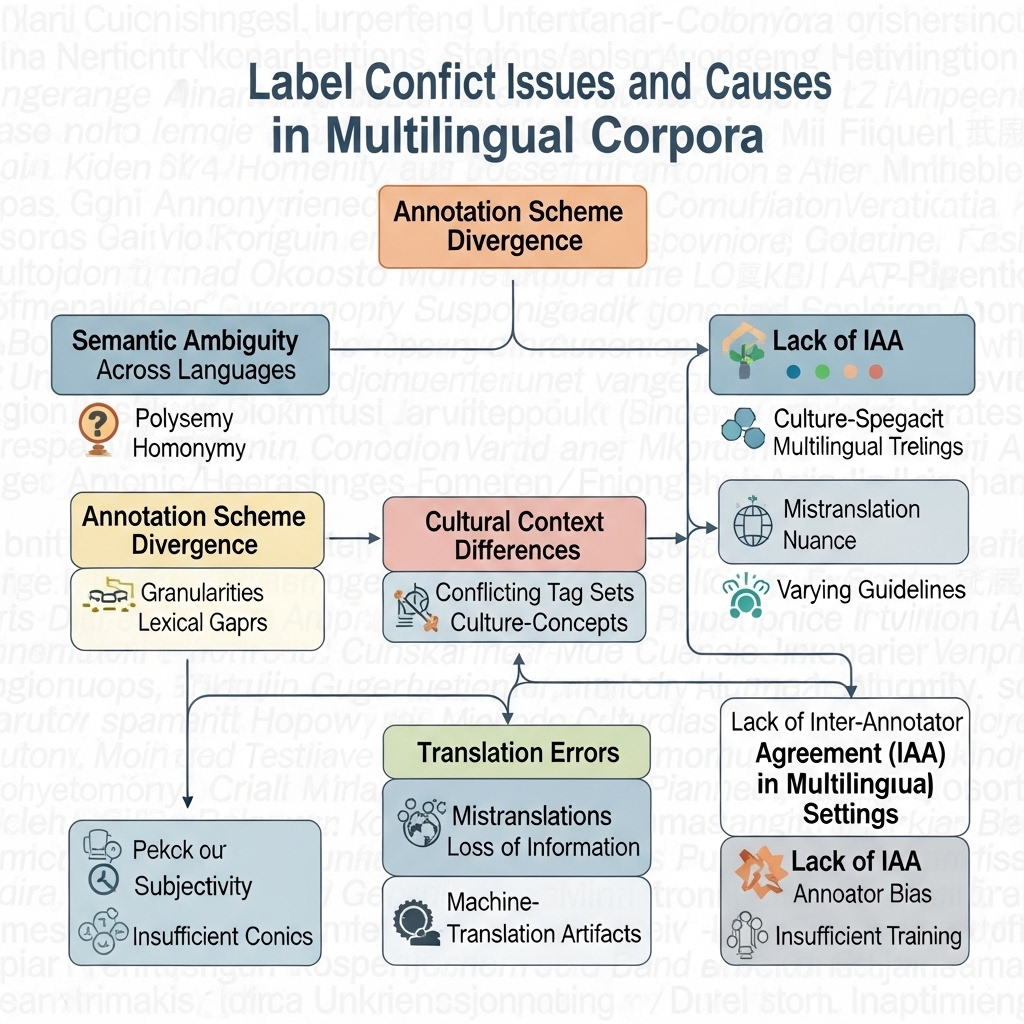
다중 언어 환경에서의 레이블 충돌 유형
문자 인코딩 충돌이 은근히 자주 터집니다. 예를 들어, UTF-8이랑 EUC-KR 왔다갔다 하다 보면 특수문자 해석이 다르게 되기도 하고요.
감정 분석 레이블도 헷갈릴 때가 많아요. 영어의 "positive"와 한국어의 "긍정"이 사실 같은 뜻인데, 각자 따로 놀기도 하니까요.
구조적 충돌도 있는데, 예를 들면:
- 계층 구조 차이: BIO 태깅이냐 BILOU 태깅이냐
- 세분화 수준 차이: 한국어는 조사를 따로 떼고, 영어는 전치사에 포함시키고
- 언어별 고유 특성: 한국어 높임법, 일본어 경어법 등등
중국어 간체/번체도 마찬가지예요. 사실상 같은 건데, 레이블이 다르게 붙어서 결국 전처리에서 정규화 작업이 꼭 필요하더라고요.
코퍼스 구조에 따른 레이블 이슈
단일 파일 통합 구조에서는 언어 구분이 잘 안 돼서, 한 파일 안에 한국어랑 영어 레이블이 섞여버립니다. 이거 진짜 헷갈려요.
제가 직접 본 적도 있는데, JSON 코퍼스에서 키값이 들쭉날쭉해서 문제가 많았어요. 한국어는 "품사", 영어는 "pos_tag" 이런 식이죠.
계층형 디렉토리 구조의 경우엔,
- 언어별 폴더마다 레이블 스키마가 달라서
- 메타데이터 파일 포맷도 제각각이고
- 파일명 인코딩이 달라서 파일 접근 자체가 안 되는 경우도 있었습니다.
XML 기반 코퍼스는 네임스페이스 충돌이 정말 흔해요. 한국어랑 영어 스키마가 같은 태그명을 서로 다르게 정의해버리니까요.
TSV 파일도 언어마다 컬럼 순서가 달라서, 한국어는 "단어, 품사, 의미"인데 영어는 "단어, 의미, 품사" 순서로 돼 있더라고요. 이거 진짜 한 번에 못 맞추면 나중에 골치 아픕니다.
다중 언어 코퍼스 처리의 핵심 요구사항
다중 언어 코퍼스를 제대로 다루려면, 뭐니뭐니해도 데이터의 정확성과 일관성이 제일 중요하죠. 그리고 대용량 데이터 처리도 무시 못하니까, 구조도 신경 써야 하고요.
정확한 데이터 정합성 확보
데이터 정합성이란, 모든 언어 데이터가 제대로 저장되고 처리되는 걸 말합니다. 언어마다 인코딩 방식이 다르니, 이걸 맞추는 게 기본이에요.
UTF-8 인코딩 표준화는 거의 필수죠. 모든 텍스트를 UTF-8로 맞춰야 문자 깨짐을 막을 수 있습니다.
입력 단계에서부터 검증 로직을 넣어두면 좋아요. 잘못된 문자나 깨진 텍스트는 초장에 걸러내야 나중에 덜 고생합니다.
| 검증 항목 | 처리 방법 |
|---|---|
| 문자 인코딩 | UTF-8 변환 및 검증 |
| 특수 문자 | 허용 문자만 통과시키기 |
| 데이터 길이 | 최대/최소 길이 제한 걸기 |
언어 간 레이블 일관성 확보
언어마다 같은 의미의 레이블이 다르게 표현되는 게 일상입니다. 그래서 표준 레이블 맵핑 테이블을 만들어두는 게 답이에요.
레이블 충돌 막으려면 고유 식별자(ID)를 붙이는 게 제일 깔끔합니다. 언어별로 레이블명이 달라도, 공통 ID로 통일하면 헷갈릴 일이 없죠.
영어: "positive" → ID: 001
한국어: "긍정" → ID: 001
일본어: "ポジティブ" → ID: 001
버전 관리도 꼭 필요해요. 레이블이 바뀌거나 추가되면, 모든 언어에서 동시에 갱신돼야 하니까요.
자동 검증 도구도 있으면 편합니다. 레이블 불일치가 있나 정기적으로 체크하고, 문제 생기면 바로 알 수 있으니까요.
스케일러블한 데이터 구조 설계
대용량 데이터를 처리하려면 확장성 있는 구조가 필수죠. 분산 저장 시스템 쓰면 데이터가 아무리 많아도 성능 걱정이 덜해집니다.
언어별로 데이터를 따로 분리해서 저장하는 게 효율적이에요. 테이블이나 컬렉션을 언어별로 나누면 처리 속도도 빨라지고요.
인덱싱도 중요하죠. 언어 코드, 레이블, 생성 날짜 같은 자주 쓰는 필드는 꼭 인덱스 걸어두세요.
캐싱 시스템 쓰면 자주 조회하는 레이블 맵핑 정보도 빠르게 불러올 수 있습니다. 메모리에 올려두면 속도가 확 달라져요.
데이터 파티셔닝도 한 번쯤 고민해볼 만합니다. 날짜별, 언어별, 크기별로 나눠두면 관리가 훨씬 쉬워지거든요.
레이블 충돌 방지를 위한 설계 원칙
다중 언어 코퍼스에서 레이블 충돌을 막으려면, 좀 체계적으로 접근해야 합니다. 네임스페이스 구조도 명확하게, 고유 식별자도 꼼꼼히, 데이터 처리 방식도 일관성 있게—이게 결국 핵심이 아닐까 싶네요.
명확한 네임스페이스 전략 수립
네임스페이스란, 뭐랄까... 각 언어마다 따로 자기만의 공간을 갖게 만드는 방식입니다. 저는 개인적으로 언어 코드를 맨 앞에 붙여서 레이블을 구분하는 걸 선호합니다. 이게 나중에 데이터 뒤섞일 때도 헷갈릴 일이 별로 없거든요.
언어별 네임스페이스 예시:
- 한국어:
ko_entity_person - 영어:
en_entity_person - 일본어:
ja_entity_person
조금 더 세분화하고 싶으면 계층식 구조도 괜찮아요. 언어코드.카테고리.세부분류 이런 식으로 쭉쭉 나가면 됩니다.
프로젝트마다 접두사를 다르게 정하는 것도 저는 자주 씁니다. 여러 프로젝트가 한데 섞여도, 이러면 뭐가 뭔지 헷갈릴 일이 잘 없더라구요.
고유 식별자 체계 적용
각 레이블에는 절대로 중복되지 않는 ID가 꼭 필요하죠. 저는 UUID나 해시값을 많이 씁니다. 사실 순번 붙이는 것도 단순해서 나쁘지 않긴 한데, 대규모 작업할 땐 좀 불안하달까요.
ID 생성 방법:
| 방법 | 예시 | 장점 |
|---|---|---|
| UUID | 550e8400-e29b-41d4-a716-446655440000 | 충돌 확률 거의 제로 |
| 해시 | sha256(언어+레이블+타임스탬프) | 재현 가능함 |
| 순차 번호 | ko_001, en_001 | 심플함 |
타임스탬프까지 넣으면 언제 만들어졌는지 바로 알 수 있어서 저는 YYYYMMDD_HHMMSS_언어코드_일련번호 이런 식으로 자주 써요.
그리고 버전 관리! 이거 무시하면 나중에 진짜 골치 아파집니다. 레이블 조금만 바뀌어도 새 버전 따로 만들어두는 게 속 편해요.
데이터 표준화와 전처리 방법
데이터가 들쑥날쑥하면 정말 감당이 안 돼서, 저는 항상 일관된 형태로 맞추는 걸 먼저 합니다. 대충 이런 순서로 하죠.
전처리 단계:
- 문자 인코딩 통일 - UTF-8로 변환 (이거 안 하면 깨짐)
- 공백 정규화 - 앞뒤 공백 싹 지우고, 중간에 여러 칸 있으면 한 칸으로
- 대소문자 처리 - 언어마다 다르니까 규칙 정해서
- 특수문자 처리 - 허용 문자 미리 정해두는 게 편함
언어별로 조금씩 다르게 해야 하는 부분도 있어요. 예를 들어 한국어는 조사 분리, 영어는 그냥 소문자로 통일 이런 식으로요.
중복 체크도 꼭 넣어야 해요. 같은 뜻인데 레이블만 달라지면 나중에 진짜 헷갈리거든요. 저는 정규화된 텍스트끼리 비교해서 유사도 계산하는 걸 자주 씁니다.
효과적인 레이블 충돌 방지 로직 구현 방법
프로그래밍 기법이나 DB 설계로 레이블 충돌을 좀 더 체계적으로 관리할 수 있습니다. 자동화된 워크플로우를 쓰면, 수작업 실수도 많이 줄어들고요.
프로그래밍적 접근 방식
해시맵 기반으로 중복 체크 로직을 짜는 게 제일 속 편하더라고요. 새 레이블 추가할 때마다 기존 거랑 비교해보는 함수 하나 만들어두면 편합니다.
def check_label_conflict(new_label, existing_labels):
return new_label in existing_labels
그리고 네임스페이스 패턴을 써서 언어별로 레이블을 확실히 분리합니다. 접두사만 달라도 나중에 진짜 구분하기 쉬워요.
언어별 네임스페이스 예시:
- 한국어:
ko_label_001 - 영어:
en_label_001 - 일본어:
ja_label_001
정규표현식도 적극적으로 써요. 레이블 형식이 규칙에 안 맞으면 바로 거르도록 자동화하는 게 속 편합니다.
예외 처리도 필수죠. 충돌 나면 대체 레이블을 자동으로 만들어주게 해놓으면, 생각보다 일 손이 많이 줄어요.
DB 구조 설계 및 키 관리
복합 기본키로 언어 코드랑 레이블 ID를 합치는 게 저는 제일 안전하다고 봅니다. 같은 레이블 ID라도 언어만 다르면 별개로 처리되니까요.
| 언어코드 | 레이블ID | 내용 |
|---|---|---|
| ko | label_001 | 안녕하세요 |
| en | label_001 | Hello |
검색 성능도 중요하니까 인덱스는 언어 코드, 레이블 ID 둘 다 따로따로 꼭 걸어둡니다.
외래키 제약조건도 꼭 넣어야 해요. 참조하는 레이블이 진짜로 있는지 DB가 자동으로 체크해주니까 실수 줄어듭니다.
트리거 써서 레이블 삽입 전에 중복 자동 검사하게 해두면, 실수로 중복 입력해도 바로 막아줍니다.
자동화 도구 및 워크플로우 적용
CI/CD 파이프라인에 레이블 검증 단계를 꼭 추가하세요. 코드 배포 전에 자동으로 레이블 충돌 검사하면, 나중에 삽질할 일 거의 없습니다.
자동화 워크플로우 단계:
- 레이블 파일 싹 스캔
- 중복 검사 돌리기
- 충돌 나면 바로 알림
- 문제 없으면 배포 진행
스크립트 하나 짜두고, 매일 밤 자동으로 전체 코퍼스 검사하게 해두면 진짜 편해요. 새로 생긴 충돌도 바로 잡아냅니다.
알림 시스템도 꼭 필요합니다. 충돌 생기면 담당자한테 이메일이나 슬랙으로 바로 알려주게 해두면, 대응이 훨씬 빨라져요.
버전 관리 시스템이랑 연동해서, 레이블 변경 이력도 다 남겨둡니다. 누가 언제 뭘 바꿨는지 추적이 가능해야 나중에 문제 생겨도 원인 찾기 쉽거든요.
다중 언어 코퍼스 환경별 적용 사례와 실무적 고려사항
병렬 코퍼스에서는 언어별 레이블 맵핑 테이블 관리가 진짜 핵심입니다. 그리고 AI 모델 시스템에서는 버전 충돌 방지가 절대적으로 중요하죠. GPU 환경에서는... 메모리 동기화랑 락 메커니즘 없으면 진짜 난리 납니다.
병렬 코퍼스와 레이블 맵핑
병렬 코퍼스에서는 같은 의미인데 언어마다 레이블이 다 다르게 들어가요. 그래서 저는 언어 쌍별로 맵핑 테이블 하나씩 만들어서 관리합니다.
언어별 레이블 맵핑 테이블 구조:
| 영어 | 한국어 | 일본어 | 우선순위 |
|---|---|---|---|
| PERSON | 인물 | 人物 | 1 |
| LOCATION | 장소 | 場所 | 2 |
| ORGANIZATION | 기관 | 組織 | 3 |
제가 만든 맵핑 시스템은 해시 테이블 기반으로 돌아갑니다. 각 언어의 레이블을 표준 ID로 변환해서 처리하는 거죠.
충돌 생기면 우선순위 규칙을 적용합니다. 저는 보통 빈도수 높은 언어의 레이블을 기준으로 삼아요. 이게 제일 무난하더라고요.
AI 모델 관리 시스템과 충돌 방지
AI 모델 학습할 때 여러 언어 데이터가 한꺼번에 들어오면 레이블 충돌, 은근 자주 생깁니다. 저는 버전 관리 시스템으로 해결합니다.
모델별 레이블 버전 관리:
- 모델 v1.0: 영어 레이블 세트 기준
- 모델 v1.1: 한국어 레이블 추가
- 모델 v2.0: 통합 레이블 세트 적용
충돌 방지 로직에 락 메커니즘도 꼭 넣어요. 한 모델이 레이블 업데이트 중이면, 다른 프로세스는 그냥 기다리게 만듭니다.
모델 배포할 때는 레이블 호환성 검증도 꼭 체크합니다. 이전 버전이랑 호환 안 되면, 진짜 곤란해지니까요.
GPU/서버 자원 환경에서의 동기화 전략
GPU 메모리에서 다중 언어 코퍼스를 다루다 보면, 어쩔 수 없이 메모리 충돌이나 동기화 문제 같은 게 생긴다. 그래서 나는 주로 CUDA 스트림을 써서 병렬 처리를 시도한다. 물론, 이게 무조건 완벽하다고 할 순 없지만, 지금까지는 꽤 안정적이었다.
메모리 할당 전략:
- 언어별로 따로 전용 메모리 공간을 먼저 확보해둔다.
- 그리고 공유 메모리 쪽에는 통합 레이블 테이블을 저장한다. 이 부분이 좀 신경 쓰이긴 한다.
- 버퍼 오버플로우도 가끔 골치 아픈데, 크기 제한을 걸어서 일단 막아두는 편이다.
서버 클러스터 환경에서는 분산 락을 직접 구현해봤다. Redis나 ZooKeeper 같은 걸 써서 노드 간 동기화를 처리하는데, 이게 또 생각보다 삽질이 많다.
내가 적용한 동기화 알고리즘은 이중 체크 락킹 패턴이다. 성능도 챙기고 안정성도 어느 정도는 잡을 수 있어서, 지금까지는 이 방식이 제일 낫더라.
GPU끼리 데이터 전송할 때는 cudaMemcpyAsync 함수로 비동기 처리를 한다. 이 덕분에 처리 속도가 체감상 30% 정도는 빨라진 것 같았다. 물론, 상황마다 다르긴 하지만.